
Linux を使用して企業にサービスを提供する場合、それらのサービスは安全で、回復力があり、スケーラブルである必要があります。素晴らしい言葉ですが、これは何を意味するのでしょうか?
「安全」とは、ユーザーが読み取り専用アクセスでも書き込みアクセスでも、必要なデータにアクセスできることを意味します。同時に、閲覧を許可されていない関係者にデータが公開されることはありません。セキュリティは欺瞞です。すべてが保護されていると思っていても、後で穴があることがわかります。プロジェクトの開始時からセキュリティを考慮した設計を行うことは、後でセキュリティを改修しようとするよりもはるかに簡単です。
「回復力がある」とは、サービスがインフラストラクチャ内の障害を許容することを意味します。サーバーのディスク コントローラーに障害が発生し、どのディスクにもアクセスできなくなり、データにアクセスできなくなる可能性があります。または、ネットワーク スイッチに障害が発生し、2 つ以上のシステムが通信できなくなっている可能性があります。この文脈において、「単一障害点」または SPOF とは、サービスの可用性に悪影響を与える障害のことです。回復力のあるインフラストラクチャとは、SPOF がないインフラストラクチャです。
「スケーラブル」とは、需要の急増を適切に処理するシステムの能力を表します。また、システムにどれだけ簡単に変更を加えることができるかにも影響します。たとえば、新しいユーザーの追加、ストレージ容量の増加、アマゾン ウェブ サービスから Google Cloud へのインフラストラクチャの移行、さらには社内での移行などです。
インフラストラクチャが 1 つのサーバーを超えて拡張されると、セキュリティ、復元力、およびスケーラビリティを向上させるためのオプションが数多く存在します。これらの問題が従来どのように解決されてきたのか、またビッグ アプリケーション コンピューティングの様相を変える利用可能な新技術にはどのようなものがあるのかを見ていきます。

読んでいるものは楽しいですか?Linux とオープンソースをもっと知りたいですか? 文字通り、届けることができます!今すぐ Linux Format をお買い得な価格で購読してください(新しいタブで開きます) 。印刷版、デジタル版、または両方を入手できますか? シンプルな年会費で世界中のご自宅までお届けします。あなたの生活をより良く、より簡単に、今すぐ購読してください(新しいタブで開きます) !
現在何が可能になっているかを理解するには、テクノロジー プロジェクトが従来どのように実装されてきたかを知ることが役立ちます。昔、つまり 10 年以上前には、企業はアプリケーションのすべてのコンポーネントを実行するためにハードウェアを購入またはリースしていました。WordPress Web サイトなどの比較的単純なアプリケーションであっても、複数のコンポーネントがあります。WordPress の場合、MySQL データベースと、Apache などの Web サーバー、および PHP コードを処理する方法が必要です。そこで、サーバーを構築し、Apache、PHP、MySQL をセットアップし、WordPress をインストールして、出発しました。
概して、それはうまくいきました。これは十分にうまく機能したため、現在でも非常に多くのサーバーがまさにそのように構成されています。しかし、それは完璧ではなく、復元力と拡張性という 2 つの大きな問題がありました。
復元力が欠如しているため、サーバーに重大な問題が発生するとサービスが失われる可能性があります。致命的な障害が発生すると Web サイトが利用できなくなることは明らかですが、Web サイトに影響を与えずに定期メンテナンスを実行する余地もありませんでした。Apache の定期的なセキュリティ アップデートをインストールしてアクティブ化するだけでも、Web サイトを数秒停止する必要があります。
復元力の問題は、「高可用性クラスター」を構築することで主に解決されました。原則として、2 台のサーバーで Web サイトを実行し、どちらかのサーバーに障害が発生しても Web サイトがダウンしないように構成することでした。たとえ個々のサーバーが復元できなかったとしても、提供されているサービスには復元力がありました。
Kubernetes の能力の一部は、Kubernetes が提供する抽象化です。開発者の観点から見ると、Docker コンテナーで実行されるアプリケーションを開発します。Docker は、Windows、Linux、またはその他のオペレーティング システムで実行されているかどうかを気にしません。同じ Docker コンテナを開発者の MacBook から取得し、変更を加えずに Kubernetes で実行できます。
Kubernetes のインストール自体は単一のマシンにすることができます。もちろん、Kubernetes の利点の多くは利用できなくなります。自動スケーリングはありません。明らかな単一障害点があるなどです。ただし、テスト環境での概念実証としては機能します。
本番環境の準備が完了したら、社内で実行することも、AWS や Google Cloud などのクラウド プロバイダーで実行することもできます。クラウド プロバイダーには、Kubernetes の実行を支援するいくつかの組み込みサービスがありますが、どれも難しい要件はありません。Google、Amazon、および独自のインフラストラクチャの間を移動したい場合は、Kubernetes をセットアップして相互に移動します。アプリケーションを一切変更する必要はありません。
そして、Linux はどこにあるのでしょうか? Kubernetes は Linux 上で実行されますが、オペレーティング システムはアプリケーションからは見えません。これは、IT インフラストラクチャの成熟度と使いやすさにおける重要な一歩です。
スラッシュドット効果
スケーラビリティの問題は少し厄介です。あなたの WordPress サイトに毎月 1,000 人の訪問者がいるとします。ある日、あなたのビジネスが Radio 4 または朝食 TV で取り上げられました。突然、20 分で 1 か月分以上の訪問者が訪れるようになります。Web サイトが「クラッシュ」するという話を聞いたことがあるでしょう。その理由は通常、スケーラビリティの欠如です。
復元力を高める 2 台のサーバーは、1 台のサーバーだけで処理できるよりも高いワークロードを管理できますが、それでも限界があります。100% の場合、2 台のサーバーに対して料金を支払うことになりますが、ほとんどの場合、両方とも完璧に動作していました。おそらく 1 人だけでサイトを運営できるでしょう。その後、John Humphrys が Today であなたのビジネスについて言及しました。負荷を処理するには 10 台のサーバーが必要ですが、それはほんの数時間のことです。
復元力とスケーラビリティの問題の両方に対するより良い解決策は、クラウド コンピューティングでした。アマゾン ウェブ サービス (AWS) または Google Cloud 上にサーバー インスタンス (アプリケーションを実行する小さなサーバー) を 1 つまたは 2 つセットアップすると、インスタンスの 1 つが何らかの理由で失敗した場合、自動的に再起動されます。自動スケーリングを正しく設定すると、ハンフリー氏が Web サーバー インスタンスのワークロードを急速に増加させた場合、ワークロードを共有するために追加のサーバー インスタンスが自動的に起動されます。その後、利息が少なくなると、追加のインスタンスは停止され、使用した分だけ支払うことになります。完璧…ですか?
クラウド ソリューションは従来のスタンドアロン サーバーよりもはるかに柔軟ですが、まだ問題があります。実行中のすべてのクラウド インスタンスを更新するのは簡単ではありません。クラウド向けの開発にも課題があります。開発者が使用しているラップトップはクラウド インスタンスに似ているかもしれませんが、同じではありません。AWS にコミットしている場合、Google Cloud への移行は複雑な作業になります。そして、何らかの理由で、単に自分のコンピューティングを Amazon、Google、または Microsoft に譲渡したくないと仮定しますか?
コンテナーは、アプリケーションとそのすべての依存関係を 1 つのパッケージにラップし、どこでも実行できるようにする手段として登場しました。Docker などのコンテナーは、クラウド インスタンス上で実行するのと同じ方法で開発者のラップトップ上で実行できますが、コンテナーの数が増加するにつれて、コンテナー フリートの管理はますます困難になります。
答えはコンテナ オーケストレーションです。これは焦点の大きな変化です。以前は、ワークロードに確実に対応できるように、物理サーバーでも仮想サーバーでも十分なサーバーがあることを確認していました。クラウド プロバイダーの自動スケーリングを使用することは役に立ちましたが、それでもインスタンスを処理していました。ロードバランサー、ファイアウォール、データストレージなどを手動で構成する必要がありました。コンテナ オーケストレーションを使用すると、そのすべて (およびそれ以上) が処理されます。必要な結果を指定し、コンテナ オーケストレーション ツールが要件を満たします。私たちは、どのようにしてほしいかではなく、何をしてほしいかを指定します。
Kuberneteになる
Kubernetes (ku-ber-net-eez) は、今日の主要なコンテナ オーケストレーション ツールであり、Google から提供されました。大規模な IT インフラストラクチャの運用方法を知っている人がいれば、Google が知っています。Kubernetes の起源は、検索エンジン、Gmail、Google マップなどを含む Google アプリケーションのほとんどを実行するために今でも使用されている Google 内部プロジェクトである Borg です。Borg は、Google が 2015 年にそれに関する論文を発表するまで秘密でしたが、この論文により、Borg が Kubernetes の背後にある主要なインスピレーションであることが非常に明らかになりました。
Borg は、Google のデータ センターの計算リソースを管理し、ハードウェア障害、リソースの枯渇、または機能停止を引き起こす可能性のあるその他の問題が発生した場合でも、本番環境とその他の両方の Google アプリケーションの実行を維持するシステムです。これは、Borg の「セル」を構成する何千ものノードとその上で実行されているコンテナを注意深く監視し、問題や負荷の変動に応じて必要に応じてコンテナを起動または停止することによって行われます。
Kubernetes 自体は Google の GIFEE (「Google のインフラストラクチャ ForEveryone Else」) イニシアチブから誕生し、Google 以外でも役立つ Borg のよりフレンドリーなバージョンとして設計されました。これは、Cloud Native Computing Foundation (CNCF) の設立を通じて 2015 年に Linux Foundation に寄贈されました。
Kubernetes provides a system whereby you “declare” your containerised applications and services, and it makes sure your applications run according to those declarations. If your programs require external resources, such as storage or load balancers, Kubernetes can provision those automatically. It can scale your applications up or down to keep up with changes in load, and can even scale your whole cluster when required. Your program’s components don’t even need to know where they’re running: Kubernetes provides internal naming services to applications so that they can connect to “wp_mysql” and be automatically connected to the correct resource.’
The end result is a platform that can be used to run your applications on any infrastructure, from a single machine through an on-premise rack of systems to cloud-based fleets of virtual machines running on any major cloud provider, all using the same containers and configuration. Kubernetes is provider-agnostic: run it wherever you want.
Kubernetes is a powerful tool, and is necessarily complex. Before we get into an overview, we need to introduce some terms used within Kubernetes. Containers run single applications, as discussed above, and are grouped into pods. A pod is a group of closely linked containers that are deployed together on the same host and share some resources. The containers within a pod work as a team: they’ll perform related functions, such as an application container and a logging container with specific settings for the application.
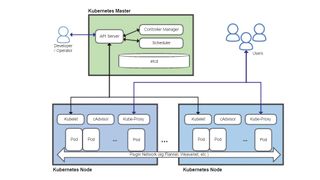
Four key Kubernetes components are the API Server, the Scheduler, the Controller Manager and a distributed configuration database called etcd. The API Server is at the heart of Kubernetes, and acts as the primary endpoint for all management requests. These may be generated by a variety of sources including other Kubernetes components, such as the scheduler, administrators via command-line or web-based dashboards, and containerised applications themselves. It validates requests and updates data stored in etcd.
The Scheduler determines which nodes the various pods will run on, taking into account constraints such as resource requirements, any hardware or software constraints, workload, deadlines and more.
The Controller Manager monitors the state of the cluster, and will try to start or stop pods as necessarily, via the API Server, to bring the cluster to the desired state. It also manages some internal connections and security features.
Each node runs a Kubelet process, which communicates with the API server and manages containers – generally using Docker – and Kube-Proxy, which handles network proxying and load balancing within the cluster.
The etcd distributed database system derives its name from the /etc folder on Linux systems, which is used to hold system configuration information, plus the suffix ‘d’, often used to denote a daemon process. The goals of etcd are to store key-value data in a distributed, consistent and fault-tolerant way.
API サーバーはすべての状態データを etcd に保持し、多くのインスタンスを同時に実行できます。スケジューラとコントローラ マネージャは、アクティブなインスタンスを 1 つだけ持つことができますが、リース システムを使用して、どの実行インスタンスがマスターであるかを決定します。これは、Kubernetes が単一障害点のない高可用性システムとして実行できることを意味します。
すべてを一緒に入れて
では、これらのコンポーネントを実際にどのように使用すればよいのでしょうか? 以下は、Kubernetes を使用して WordPress Web サイトをセットアップする例です。これを実際に実行したい場合は、おそらく、ヘルム チャートと呼ばれる事前定義されたレシピを使用することになるでしょう。これらは多くの一般的なアプリケーションで利用できますが、ここでは WordPress サイトを Kubernetes 上で稼働させるために必要な手順のいくつかを見ていきます。
最初のタスクは、MySQL のパスワードを定義することです。
kubectl create secret generic mysql-pass --from-literal=password=YOUR_PASSWORD
kubectl は API サーバーと通信し、コマンドを検証してパスワードを etcd に保存します。私たちのサービスは YAML ファイルで定義されているため、MySQL データベース用の永続ストレージが必要になります。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pv-claim
labels:
app: wordpress
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
仕様はほとんど一目瞭然です。名前フィールドとラベルフィールドは、Kubernetes の他の部分 (この場合は WordPress コンテナ) からこのストレージを参照するために使用されます。
ストレージを定義したら、事前定義されたストレージを指す MySQL インスタンスを定義できます。続いて、データベース自体を定義します。Kubernetes 内で簡単に参照できるように、そのデータベースに名前とラベルを付けます。
次に、WordPress を実行するための別のコンテナが必要になります。コンテナのデプロイメント仕様の一部は次のとおりです。
kind: Deployment
metadata:
name: wordpress
labels:
app: wordpress
spec:
strategy:
type: Recreate
戦略タイプ「再作成」は、アプリケーションを構成するコードのいずれかが変更された場合、実行中のインスタンスが削除され、再作成されることを意味します。その他のオプションには、新しいインスタンスを循環させたり、既存のインスタンスを 1 つずつ削除したりして、更新プログラムの展開中にサービスの実行を継続できるようにする機能などが含まれます。最後に、PHP コードと Apache で構成される WordPress 自体のサービスを宣言します。これを宣言する YAML ファイルの一部は次のとおりです。
metadata:
name: wordpress
labels:
app: wordpress
spec:
ports:
- port: 80
selector:
app: wordpress
tier: frontend
type: LoadBalancer
サービス タイプを LoadBalancer として定義している最後の行に注目してください。これは、Kubernetes の外部でサービスを利用できるようにするよう Kubernetes に指示します。この行がなければ、これは単に内部の「Kubernetes のみ」のサービスになります。以上です。Kubernetes はこれらの YAML ファイルを必要なものの宣言として使用し、クラスターを「望ましい」状態にするために必要に応じてポッド、接続、ストレージなどをセットアップします。
これは必然的に Kubernetes の高レベルの概要にすぎず、システムの詳細や機能の多くは省略されています。自動スケーリング (クラスターを構成するポッドとノードの両方)、cron ジョブ (スケジュールに従ってコンテナーを開始)、Ingress (HTTP ロード バランシング、書き換え、SSL オフロード)、RBAC (ロールベースのアクセス制御) については説明しました。 、ネットワーク ポリシー (ファイアウォール) など。Kubernetes は非常に柔軟性があり、非常に強力です。新しい IT インフラストラクチャにとって、Kubernetes は有力な候補となるはずです。
資力
Docker に詳しくない場合は、ここから始めてください: https://docs.docker.com/get-started (新しいタブで開きます)。
アプリのデプロイとスケーリングに関する対話型のチュートリアルがここにあります: https://kubernetes.io/docs/tutorials/kubernetes-basics (新しいタブで開きます)。
クラスターの構築方法については、https://kubernetes.io/docs/setup/scratch (新しいタブで開きます)を参照してください。
https://tryk8s.com (新しいタブで開きます)で無料の Kubernetes クラスターを試すことができます。
最後に、Google による Borg の使用と、それが Kubernetes の設計にどのような影響を与えたかについての優れた概要を記載した長い技術文書を、ここで詳しく読むことができます: https://storage.googleapis.com/pub-tools-public-publication-data/ pdf/43438.pdf (新しいタブで開きます)。
Tiger Computingについて詳しくは、こちら(新しいタブで開きます)をご覧ください。

読んでいるものは楽しいですか?Linux とオープンソースをもっと知りたいですか? 文字通り、届けることができます!今すぐ Linux Format をお買い得な価格で購読してください(新しいタブで開きます) 。印刷版、デジタル版、または両方を入手できますか? シンプルな年会費で世界中のご自宅までお届けします。あなたの生活をより良く、より簡単に、今すぐ購読してください(新しいタブで開きます) !