
データマイニングの仕組み
買い物をするたびに、その痕跡が残ります。同様に、ウェブをサーフィンするときも、フィットネス トラッカー(新しいタブで開きます)を装着するときも、銀行にクレジットを申請するときも同様です。実際、もし私たちがそれに触れることができたら、溺れてしまうでしょう。IBM (新しいタブで開きます)によると、私たちが毎日生成するデータは、合計で計り知れない 2.5 京バイト (「25」の後に 17 個のゼロが続く) になります。私たちはこのデータを非常に速く作成しているため、現在世界中にあるデータの 90% がわずか過去 2 年間に作成されたものであると推定されています。この「ビッグデータ」は数十億ドルの価値がある世界的なリソースであり、あらゆる企業や政府がそれを手に入れたいと考えていますが、それには十分な理由があります。
データは、私たちの日常生活、つまり私たちの選択、購入、誰と話し、どこに行き、何をしたかのデジタル履歴です。私たちは以前、モノのインターネット(新しいタブで開きます) (IoT) と、「パーベイシブ コンピューティング」が私たちの生活様式をどのように根本的に変えるかについて考察しました。IoT によってデータの生成と取得がさらに爆発的に増加することは保証できます。クラウド ストレージのブームのおかげで、私たちはすでにこのデータをできるだけ早く片付けています。
しかし、データそれ自体はほとんど役に立ちません。データから抽出した情報は、テロの脅威の可能性を政府に事前に警告したり、地元の青果店で次に何を買うかを予測したりすることまで、あらゆることができるのです。利用可能な膨大な量のデータは人間だけで解読する能力をはるかに超えており、それを処理するにはコンピューター処理が必要です。そこで「データ マイニング」の概念が登場します。
機械学習

実際、「データ マイニング」は、実際には「機械学習」と呼ばれるコンピューティングの魅力的な分野のバズワードであり、それ自体が人工知能 (AI) から派生したものです。ここで、コンピューターは特別なコード関数または「アルゴリズム」を使用して、データの山を処理し、そこから情報を生成または「学習」します。
これは現在、先駆的な研究が急成長している分野であり、250 年以上前に初めて発見された数学的手法も組み込まれています。
ある点では、プライバシーやデータからマイニングされた情報がどのように使用されるかに関する倫理的懸念が高まっており、データ マイニングに少し影が落ちています。しかし、すべてが「テロ計画とショッピングカート」ではありません。データマイニングは、気象予測から医学研究に至るまで、科学分野で多用されており、乳がんの再発を予測したり、糖尿病の発症の指標を見つけるために使用されたりしています。
スタンフォード大学のFolding@Home (新しいタブで開きます)疾患研究プロジェクトは、癌、パーキンソン病、アルツハイマー病の治療法を探索する、あなたも参加できる地球規模のデータマイニングです。
基本的に、機械学習とは、データ内のパターンを見つけたり、意思決定や予測を行うことを可能にする「ルール」を学習したり、状況やアプリケーションにおける要素間のリンクや「関連性」を見つけたりすることです。
無料ソフトウェアを入手
現在、機械学習は、大量のコンピューター、山積みのクラウド ストレージ、高価な専用ソフトウェアを備えた研究室で行われていると考えているかもしれません。確かにその通りですが、これは自宅でもできることです。さらに、かなりの量の機械学習ソフトウェアが無料で入手できます。「Hadoop」や「R」などの一般的な例は、大量のデータを処理するための強力なフレームワークを提供しますが、初めて使用する場合は少し困難になる可能性があります。そして、ホールデン対フォード、あるいは Android 対 iOS のように、さまざまなソフトウェアの熱烈な支持者がいる分野です。
基本を学ぶためによく使用されるアプリの 1 つは、ニュージーランドのワイカト大学によって開発されたWEKA (新しいタブで開きます)です。Hadoop と同様に、Java プログラミング言語を使用して構築されているため、Windows、Linux、または Mac OS X コンピュータで実行できます。完璧ではありませんが、グラフィカル ユーザー インターフェイス (GUI) は確かに役に立ちます。
機械学習の仕組み

機械学習は、学習したい状況を表すいわゆる「データセット」から始まります。これはスプレッドシートと考えてください。列には一連のメジャーまたは「属性」があり、各行は学習したい物事または「概念」の例または「インスタンス」を表します。
たとえば、糖尿病の発症の指標を探している場合、それらの属性には、患者の体格指数 (BMI)、血糖値、その他の医学的要因が含まれる可能性があります。各インスタンスには、1 人の患者の属性セットが含まれます。この状況では、データセットには、患者が糖尿病を発症したかどうかを示す結果または「クラス」属性も含まれます。
別の患者が診断のために来院し、その患者が糖尿病のリスクがあるかどうかを知りたい場合、機械学習は、データセットの学習とその人の測定された医学的属性に基づいて、その可能性を予測するのに役立つルールを開発できます。
ルールはどのようなものですか?
私たちが TechRadar で愛用している非常にクールなツールの 1 つは、ソーシャル ネットワーク サービスを組み合わせてリンクされた機能を実行するプログラムであるIFTTT (新しいタブで開きます) (If This then That) です。名前が示すように、「イベントが発生したら、何かを実行する」という単純な「if-then」プログラミングステートメントに基づいて動作します。
機械学習の基本ルールは同じ線に沿っています。イベント X が発生すると、結果は Y になります。または、一連のイベントである可能性があります。X、Y、Z が発生した場合、結果は A、または A、B、C になります。 。
これらのルールは、私たちが学びたい概念について何かを教えてくれます。しかし、ルールが何を教えてくれるかと同じくらい重要なのは、ルールがどれだけ正確であるかということです。ルールの精度は、正しい結果をもたらすためにルールにどの程度の信頼を置けるかを明らかにします。
毎回正しい答えが得られる優れたルールもあれば、絶望的なルールもあれば、その中間のルールもあります。また、「過剰適合」と呼ばれる複雑な問題も発生します。これは、一連のルールが学習元のデータセットでは完全に機能しますが、与えられた新しい例やインスタンスではパフォーマンスが低下することを意味します。これらはすべて、機械学習とそれを使用するデータ サイエンティストが考慮する必要があることです。
基本的なアルゴリズム
機械学習関数または「アルゴリズム」は数十種類あり、その多くは非常に複雑です。ただし、「ZeroR」と「OneR」という、すぐに学習できる 2 つの単純な例があります。WEKA アプリを使用してそれらを表示しますが、手動で計算して、それらがどのように機能するかを確認します。
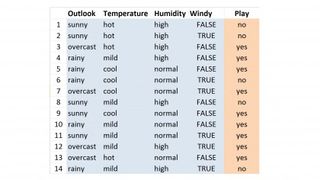
WEKA パッケージには多数のサンプル データセットが含まれており、その 1 つは非常に小さな「weather.nominal」データセットで、その時点の一連の気象現象を考慮して、特定の日にゴルフがプレーされるかどうかを示す 14 のインスタンスが含まれています。見通し、気温、湿度、風、遊びという 5 つの尺度または「属性」があります。この最後のものは出力または「クラス」属性で、その日にゴルフが行われたか (yes)、行われなかった (no) かを示します。
ゼロイン
ZeroR は世界で最も単純なデータ マイニング アルゴリズムです。非常に単純なため、これを「アルゴリズム」と呼ぶのは少し失礼ですが、適切なアルゴリズムが構築することを望むベースライン精度レベルを提供します。
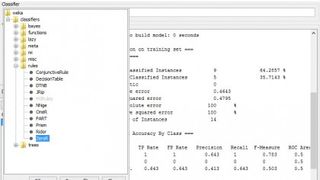
これは次のように機能します。上の画像の気象データを確認し、その「play」クラス属性を調べて、「yes」と「no」の値の数を数えます。9 つの「はい」の値と 5 つの「いいえ」の値が見つかるはずです。「はい」値の割合は、14 件中 9 件です。つまり、別の例があり、ゴルフが行われるかどうかを予測したい場合は、「はい」と答えるだけで、14 回中 9 回、つまり 64.2% の確率で的中することができます。言い換えれば、ZeroR は単に最も人気のあるクラス属性値を選択するだけです。
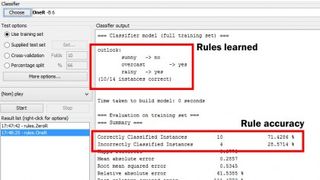
これは WEKA でテストできます。PC に Java ランタイム エンジン (JRE) がインストールされていることを確認してから、WEKA をダウンロードしてインストールし、アプリを起動します。「エクスプローラー」アイコンをクリックして学習ウィンドウを起動します。WEKA は ARFF と呼ばれる修正された CSV (コンマ区切り変数) 形式を使用しており、サンプル データセットは /program files/weka-3-x/data サブフォルダーにあります。Explorer ウィンドウで、[ファイルを開く] ボタンをクリックし、「weather.nominal」データセットを選択します。次に、[分類] タブをクリックすると、[選択] ボタンの横の [分類子] テキスト ボックスに「ZeroR」がすでに表示されているはずです。左側のコントロール パネルの [テスト オプション] の下にある [トレーニング セットを使用する] の横にあるラジオボタンをクリックし、最後に [開始] ボタンを押します。
ほぼ即座に、[分類子出力] ウィンドウに結果が表示されます。下にスクロールすると、ZeroR はデフォルトで「yes」クラス値を選択し、その後「正しく分類されたインスタンス」の横に「9」と「64.2857%」が表示されることがわかります。要するに、WEKA は以前に行ったのと同じことを行っただけです。つまり、「はい」と「いいえ」のクラス値を数え上げ、最も一般的なものを選択しました。
すべてを支配する 1 つのルール
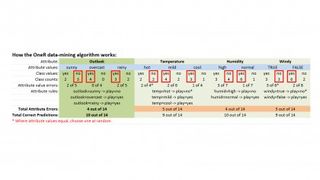
この例では、ZeroR により 64.2% の基本レベルの学習精度が得られますが、それよりももう少し優れた精度が得られるとよいでしょう。ここで OneR アルゴリズムが登場します。これは「分類ルール学習器」と呼ばれ、トレーニング データセットから学習した内容に基づいて、将来のインスタンスの結果を決定または「分類」できるようにするルールを生成します。
上の OneR テーブルを見ると、それがどのように機能するかがわかります。各気象データセット属性には、少数の可能な値があります。Outlook の場合、「晴れ」、「曇り」、「雨」です。温度については、「熱い」、「マイルド」、「クール」などです。属性値ごとに個別のリストを作成し、得られる「はい」と「いいえ」の結果の数に注目して、インスタンス内で各値が何回出現するかを数えます。
たとえば、14 件のインスタンスを調べてみると、見通しが晴れているインスタンスが 5 件あり、2 件の「はい」と 3 件の「いいえ」の結果が得られることがわかります。同様に、「見通し = 曇り」では「賛成」票が 4 票、「いいえ」票は 0 票でした。次に、他のすべての属性についても同様に行います。
次に、エラーをカウントアップします。これらは各属性値の小さい方のカウントであるため、やはり、「outlook = Sunny」の場合、「yes」のカウントは 2 つだけです。「見通し = 曇り」の場合、「いいえ」の数は 0 で、「見通し = 雨」の場合、「いいえ」の数は 2 になります。表の赤いボックスは、各属性値の最も一般的なクラス値を示しています。これらに基づいて、最初の「Outlook」ルールのセットを作成します。
見通し = 晴れ -> 遊び = いいえ 見通し = 曇り -> 遊び = はい 見通し = 雨 -> 遊び = いいえ
繰り返しますが、他の属性についても同様に行います。私たちが行っていることは、各属性値で最も人気のあるクラス値を取得し、それをその属性と値のペアに割り当ててルールを作成することです。つまり、この例では、見通しが「晴れ」であると、プレイが「いいえ」になるというようになります。 。次に、他の 3 つの属性ごとにこれを繰り返します。その後、各属性値の「エラー」数を合計するため、Outlook は 2 + 0 + 2、合計 4/14 (4/14) となります。気温については 5/14、湿度については 4/14、風については 5/14 が得られます。
ここで、エラー数が最小の属性を選択します。この例では、エラー数が 14 件中 4 件の 2 つの属性 (Outlook と Humidity) があるため、どちらかを選択できます。最初の属性である上記の「Outlook」属性ルールセットを使用しました。
これが「OneR」(ワンルール)分類ルールセットになります。このルールをトレーニング データセットに使用すると、14 件中 10 件、つまり 71.5% 弱を正確に予測します。ZeroR では 64.2% が得られたため、OneR ではより高い精度が得られます。これは私たちが望んでいることです。
新しいルールの使用
新しいインスタンスが与えられたとします。見通しは雨、気温は穏やか、湿度は高く、風が強いという予想は誤りです。「遊び」とは何か――ゴルフはプレーされるのか、されないのか。私たちの OneR ルールでは、天気が雨の場合はプレーは「ノー」であると定めているため、それが私たちの答えです。この例では、今日はゴルフが開催されない可能性が非常に高くなります (約 71.5%)。
[選択] ボタンをクリックし、[ルール] リストから [OneR] を選択して、WEKA で OneR 分類テストを実行します。[スタート] ボタンを押すと、同じルールのリスト、正しく分類されたインスタンスの数が 10 件、割合が 71.4286 であることが表示されます。それはまさに私たちが以前に計算したものです。
氷山の一角
確かに、気象現象に基づいてゴルフが行われる日を予測することで何百万も儲けたり、世界を救ったりするつもりはありません。しかし、もしあなたが気象学者であれば、現在の気象状況が大規模なひょう雨を引き起こす可能性があるかどうかを判断するのであれば、データマイニング技術 (確かに、ここで見たものよりも複雑です) がこれらの答えに役立ちます。
機械学習は、世界中でコンピューター研究のブームとなっている分野であり、私たちを取り巻く情報過多の「データによる死」を理解することを目的としています。ここではほんの表面をなぞっただけですが、次回インターネットにアクセスしたり、ショッピングに行ったりするときに、私たちが生成したデータがどうなるかについてよりよく理解できると思います。